but at that graphic i got a bad feeling
when i read that below text:
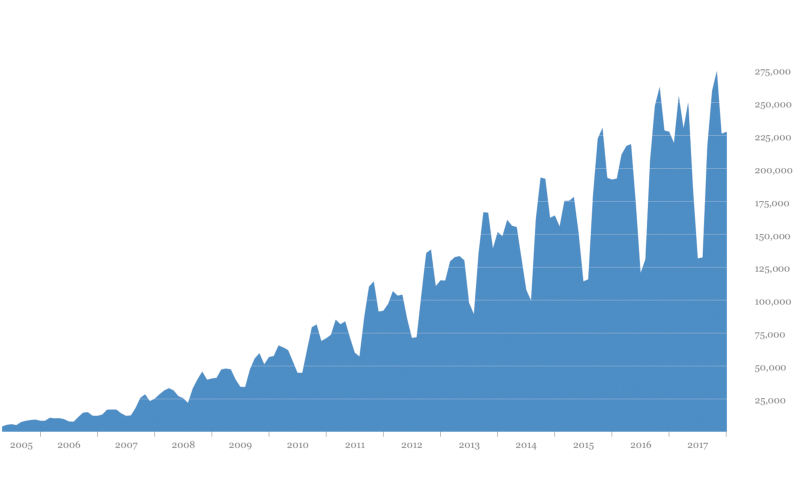
Unique monthly users of the Processing software from 2005–2017. [Image description: Blue diagram showing dates correlated with the number of people who are using the Processing software each month. The diagrams show that the number of people using the Processing software has increased year by year.]
DOES the processing program report back when it is used???
well, i think it might be something about downloads of the code… what actually might be confusing as if there is one user, and there are 3 versions he might do 3 download, what are not 3 users!
and why the user/month fall down every year to about 2/3
is using processing a seasonal thing like
summer i play football, winter i play computer with processing?
ok, the average reader might look at it with different eyes.
Checking for updates, or “why is Processing connecting to the network?”
After you double-click Processing, it will check the site for updates. This is helpful so that we can keep people aware of the frequent updates to Processing.
In so doing, it also sends a random number that identifies yours as a unique machine (but sends no personal information to us). This really helps us get a general idea of how many people are using the software, which is very important for things like writing grants so that we can keep Processing free.
Starting with Processing 3, we also send a list of what Libraries, Modes, and Tools that you have installed. We added this because it was difficult during the 3.0 release process because we had no information about what’s used most commonly across the hundreds of thousands of people who use Processing. We wanted to figure out where to concentrate what little volunteer time we had toward helping authors of contributions to get them updated, or knowing when we might need to pick up the slack if an author had disappeared.
If the network connection causes you trouble, or if you’re exceptionally paranoiduncomfortable with sharing the list of things you’ve installed using the Contribution Manager (the dialog box that shows up when you do “Add Library…” or “Add Mode…”), it can be shut off inside the Preferences window. Shutting off the update checks also means that the Contribution Manager will not work, because it needs access to the network as well. This also means that you’ll need to manually install Libraries, Modes, and Tools.
This seems pretty clear and comprehensive. Information on version. libraries, modes, and tools is all being tracked per-machine using anonymous randomly generated IDs. To stop that, uncheck the box in preferences.
I should mention one potential privacy concern – if you are developing libraries and testing them in PDE, AND if you want their names to be completely secret, THEN you shouldn’t install them in PDE while the Contributions manager is enabled. Turn it off.
So, if you really don’t trust the people at ProcessingFoundation, don’t use Contributions Manager while developing and installing libraries with names like this:
-a- i linked to this in my post above already,
so we both know it is out there.
-b- we also know that most programs do something like this,
( actually not “the” programs, the companies! )
and the “new” laws not protect you from this, but they do require
that the user is made well aware of this…
-c- so my point i not that it is like this, my point is that the processing IDE 3.4
not has the required legal blabla at first startup
and a link to a better readable TOS / privacy statement…
also it could even do better than microsoft and co
by allowing to disable this “reporting”
at the “installation”, in case the user is “paranoid”.
so my concern is to protect the foundation and i want to help by pointing out that:
THIS SITE and the here “sold” product ( processing IDE )
is years behind the today’s required dealing with users
( and that legal requirements are by far not good at all )
and even in case the lawyers would says we are inside the limits of GDPR
is that a reason NOT to do it better?
and pls. not give me a " if you not like it, not use it"
would not be fair.
I would never say that. Processing is open source and directed by a non-profit – if you have suggestions for how to make the software or the docs better, I think you should open an issue and contribute them!
However, I am not a lawyer – I can’t evaluate what you are saying about “years behind the today’s required.” I have no idea if that is true or not. I was only responding from a practical point of view – that I personally don’t see many practical privacy concerns in the kind of anonymized data they are describing.
Sure – I think that’s a fine idea. You should propose it as a feature request / pull request.
Another option between “on” and “off” might be be “do not track” – e.g. allowing all PDE’s that turn on “do not track” to contact Contributions Manager as “id=0”. User would still get download tools; Processing would still get data, but aggregated only, and with less ability to count individual installs.
The disadvantage for Processing is that I believe (?) they use those use statistics to argue about impact when applying for funding and support – e.g. as a participant in Google Summer of Code – so a format that encouraged most users to turn off this harmless feature might negatively impact the community (because Processing wouldn’t be able to use impact as effectively to argue for support and program participation).