pleek
September 10, 2025, 8:52am
1
Hello everybody..!!
I’m coding a visualiser for composing graphics on receipt tickets.
For this, I’m trying to text(“░ ▓ ├ ≡ Σ ►_-
I tried:
The app’s createFont tool, to create a .vlw with ALL the characters, using the most common fonts such as arial or Verdana (which I assume have a very large character set). The file can go as heavy as 100Mb. Sometimes it crashes midway. Others, the special characters just don’t appear.
using createFont() function to dynamically create the font. I. don’t know the extension of the characters set that it creates. Same result as before.
Could you point me to the right direction? thanx in advance!
PFont type;
void setup(){
size(800,800);
printArray(PFont.list());
type = createFont("Verdana", 48);
textSize(25);
println("░▒▓█▄▌▐ éèàuü ♂░►_-♠*◙▀▲∕●MN@#$");
fill(0);
}
void draw(){
background(200);
text("░▒▓█▄▌▐éèàuü ♂░►_-♠*◙▀▲∕●MN@#$", mouseX, mouseY);
}
glv
September 10, 2025, 3:50pm
2
Hello @pleek ,
This will lead in the right direction:
See the reference:createFont() / Reference / Processing.org You are missing an important line!
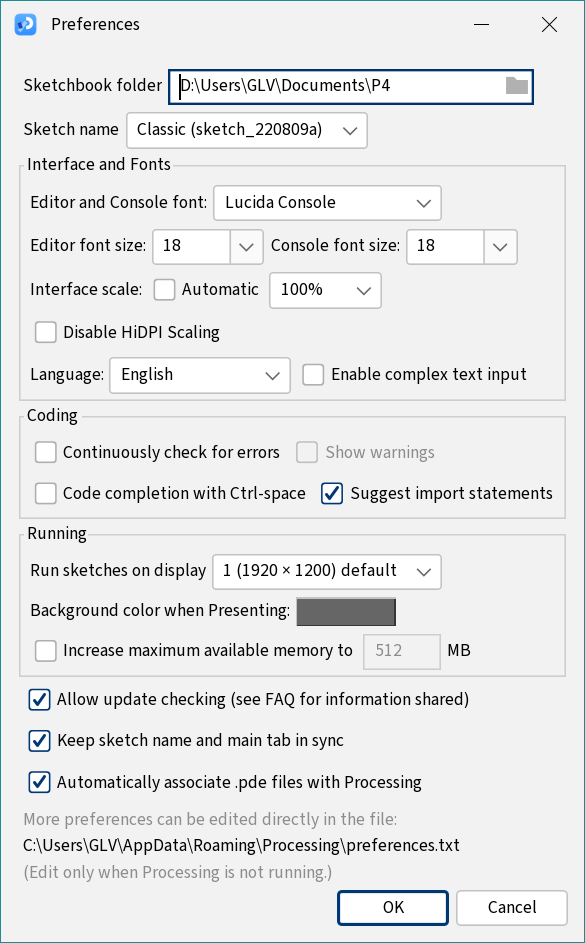
The Preferences… will show you the fonts being used:
console font does not always display the same as the editor font :
Try using the editor font for the sketch font if it displays the fonts correctly which it did in my code.
And voila!
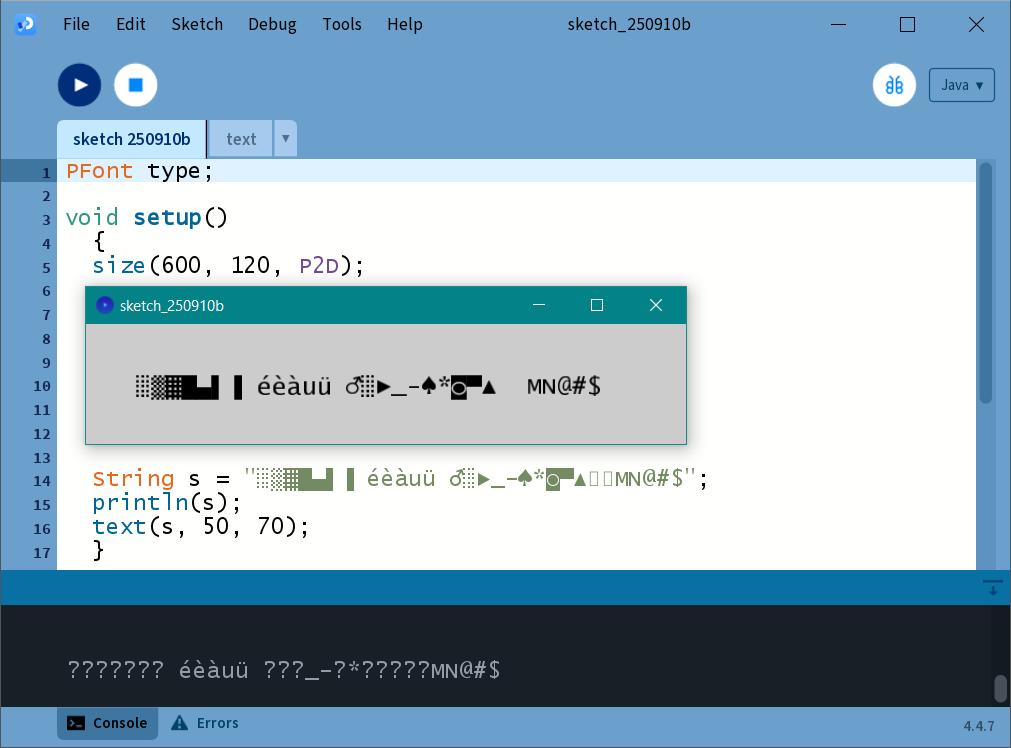
Code to complete:
void setup()
{
size(600, 120, P2D);
type = createFont("Choose a font here!", 48);
// Missing an important line here!
textSize(25);
fill(0);
String s = "░▒▓█▄▌▐ éèàuü ♂░►_-♠*◙▀▲∕●MN@#$";
println(s);
text(s, 50, 70);
}
There are still some characters missing!
You will have to find a font that suits your needs.
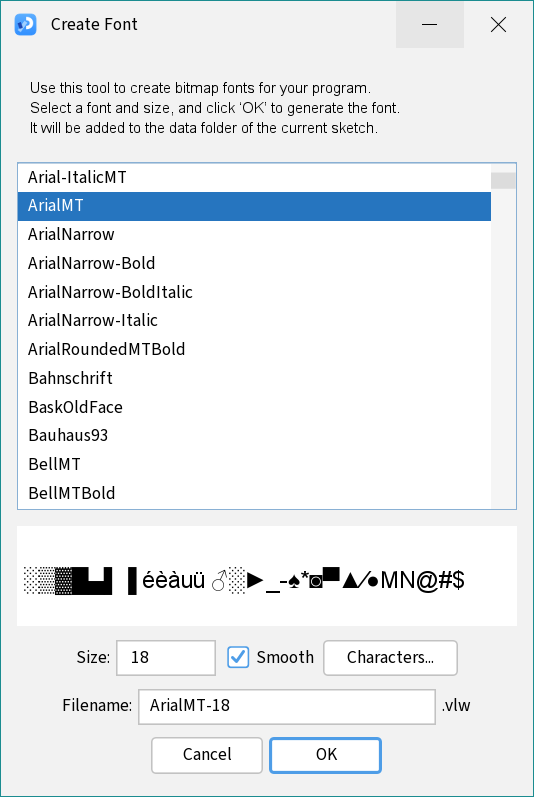
Try using the Create Font…
:)
pleek
September 11, 2025, 1:04pm
3
Hey @glv ..!!!
Thanx for the reply.!
Indeed, missing 1 very important line which changed it all..!! ahh, how I love programming…
And also, your editor <=> sketch font trick is neat…!
pleek
November 5, 2025, 4:01pm
4
AloAlo.!!!
Thanx again for the help..! In the end, the processing sketch wasn’t finished cuz I had to quickly switch the development to Arduino.
I thought I’d post here some code that really made things easier for me and might help others with their Thermal Printer projects (model CSN-A2, other xxx-A2, or like the one from Adafruit ).
It a piece of code for Arduino that let’s you directly write a string with special character in the IDE, and then transforms that into the Thermal Printer’s character table CP437 (one of the standards). Normally, you can’t just write these character in the code and then go thermalPrinter.println(“░├ Θ ô ï è ”). This little function makes it possible.
The code was generated after a pretty interesting conversation with Claude.AI. ..!! Thankfully, cuz it would have been a lot of boring lines of code..
Hope it’s useful..!
Call:
thermalPrinter.println( convertToCP437("░_▒_▓_█") );
Definition:
String convertToCP437(String input) {
String output = "";
output.reserve(input.length()); // Pre-allocate memory
for (int i = 0; i < input.length(); i++) {
byte currentByte = (byte)input.charAt(i);
if (currentByte < 128) {
// Regular ASCII (0-127)
output += char(currentByte);
} else if (currentByte == 0xC2 && i + 1 < input.length()) {
// UTF-8 two-byte sequence starting with 0xC2 (Latin-1 Supplement)
i++; // Move to next byte
byte nextByte = (byte)input.charAt(i);
switch (nextByte) {
case 0xA0: output += char(255); break; // Non-breaking space → 255
case 0xA1: output += char(173); break; // ¡ → 173
case 0xA2: output += char(155); break; // ¢ → 155
case 0xA3: output += char(156); break; // £ → 156
case 0xA4: output += char(15); break; // ¤ → 15 (generic currency)
case 0xA5: output += char(157); break; // ¥ → 157
case 0xA6: output += char(179); break; // ¦ → 179 (broken bar)
case 0xA7: output += char(21); break; // § → 21
case 0xA8: output += char(249); break; // ¨ → 249 (diaeresis)
case 0xA9: output += char(184); break; // © → 184
case 0xAA: output += char(166); break; // ª → 166
case 0xAB: output += char(174); break; // « → 174
case 0xAC: output += char(170); break; // ¬ → 170
case 0xAD: output += char(240); break; // Soft hyphen → 240
case 0xAE: output += char(169); break; // ® → 169
case 0xAF: output += char(238); break; // ¯ → 238 (macron)
case 0xB0: output += char(248); break; // ° → 248
case 0xB1: output += char(241); break; // ± → 241
case 0xB2: output += char(253); break; // ² → 253
case 0xB3: output += char(252); break; // ³ → 252
case 0xB4: output += char(239); break; // ´ → 239 (acute accent)
case 0xB5: output += char(230); break; // µ → 230
case 0xB6: output += char(244); break; // ¶ → 244
case 0xB7: output += char(250); break; // · → 250
case 0xB8: output += char(247); break; // ¸ → 247 (cedilla)
case 0xB9: output += char(251); break; // ¹ → 251
case 0xBA: output += char(167); break; // º → 167
case 0xBB: output += char(175); break; // » → 175
case 0xBC: output += char(172); break; // ¼ → 172
case 0xBD: output += char(171); break; // ½ → 171
case 0xBE: output += char(243); break; // ¾ → 243
case 0xBF: output += char(168); break; // ¿ → 168
default:
output += char(currentByte);
output += char(nextByte);
break;
}
} else if (currentByte == 0xC3 && i + 1 < input.length()) {
// UTF-8 two-byte sequence starting with 0xC3 (Latin Extended)
i++; // Move to next byte
byte nextByte = (byte)input.charAt(i);
switch (nextByte) {
// Uppercase letters
case 0x80: output += char(183); break; // À → 183
case 0x81: output += char(181); break; // Á → 181
case 0x82: output += char(182); break; // Â → 182
case 0x83: output += char(199); break; // Ã → 199
case 0x84: output += char(142); break; // Ä → 142
case 0x85: output += char(143); break; // Å → 143
case 0x86: output += char(146); break; // Æ → 146
case 0x87: output += char(128); break; // Ç → 128
case 0x88: output += char(212); break; // È → 212
case 0x89: output += char(144); break; // É → 144
case 0x8A: output += char(210); break; // Ê → 210
case 0x8B: output += char(211); break; // Ë → 211
case 0x8C: output += char(222); break; // Ì → 222
case 0x8D: output += char(214); break; // Í → 214
case 0x8E: output += char(215); break; // Î → 215
case 0x8F: output += char(216); break; // Ï → 216
case 0x90: output += char(209); break; // Ð → 209
case 0x91: output += char(165); break; // Ñ → 165
case 0x92: output += char(227); break; // Ò → 227
case 0x93: output += char(224); break; // Ó → 224
case 0x94: output += char(226); break; // Ô → 226
case 0x95: output += char(229); break; // Õ → 229
case 0x96: output += char(153); break; // Ö → 153
case 0x97: output += char(158); break; // × → 158
case 0x98: output += char(157); break; // Ø → 157
case 0x99: output += char(235); break; // Ù → 235
case 0x9A: output += char(233); break; // Ú → 233
case 0x9B: output += char(234); break; // Û → 234
case 0x9C: output += char(154); break; // Ü → 154
case 0x9D: output += char(237); break; // Ý → 237
case 0x9E: output += char(232); break; // Þ → 232
case 0x9F:
output += char(225);
break; // ß → 225
// Lowercase letters
case 0xA0: output += char(133); break; // à → 133
case 0xA1: output += char(160); break; // á → 160
case 0xA2: output += char(131); break; // â → 131
case 0xA3: output += char(198); break; // ã → 198
case 0xA4: output += char(132); break; // ä → 132
case 0xA5: output += char(134); break; // å → 134
case 0xA6: output += char(145); break; // æ → 145
case 0xA7: output += char(135); break; // ç → 135
case 0xA8: output += char(138); break; // è → 138
case 0xA9: output += char(130); break; // é → 130
case 0xAA: output += char(136); break; // ê → 136
case 0xAB: output += char(137); break; // ë → 137
case 0xAC: output += char(141); break; // ì → 141
case 0xAD: output += char(161); break; // í → 161
case 0xAE: output += char(140); break; // î → 140
case 0xAF: output += char(139); break; // ï → 139
case 0xB0: output += char(208); break; // ð → 208
case 0xB1: output += char(164); break; // ñ → 164
case 0xB2: output += char(149); break; // ò → 149
case 0xB3: output += char(162); break; // ó → 162
case 0xB4: output += char(147); break; // ô → 147
case 0xB5: output += char(228); break; // õ → 228
case 0xB6: output += char(148); break; // ö → 148
case 0xB7: output += char(246); break; // ÷ → 246
case 0xB8: output += char(155); break; // ø → 155
case 0xB9: output += char(151); break; // ù → 151
case 0xBA: output += char(163); break; // ú → 163
case 0xBB: output += char(150); break; // û → 150
case 0xBC: output += char(129); break; // ü → 129
case 0xBD: output += char(236); break; // ý → 236
case 0xBE: output += char(231); break; // þ → 231
case 0xBF: output += char(152); break; // ÿ → 152
default:
output += char(currentByte);
output += char(nextByte);
break;
}
} else if (currentByte == 0xCE && i + 1 < input.length()) {
// UTF-8 two-byte sequence for Greek letters (0xCE)
i++; // Move to next byte
byte nextByte = (byte)input.charAt(i);
switch (nextByte) {
case 0x91: output += char(228); break; // Α (Alpha) → 228
case 0x92: output += char(229); break; // Β (Beta) → 229
case 0x93: output += char(226); break; // Γ (Gamma) → 226
case 0x94: output += char(235); break; // Δ (Delta) → 235
case 0x98: output += char(233); break; // Θ (Theta) → 233
case 0x9B: output += char(227); break; // Λ (Lambda) → 227
case 0xA0: output += char(228); break; // π (pi) → π (special case)
case 0xA3: output += char(229); break; // Σ (Sigma) → 229
case 0xA6: output += char(230); break; // Φ (Phi) → 230
case 0xA9: output += char(234); break; // Ω (Omega) → 234
case 0xB1: output += char(224); break; // α (alpha) → 224
case 0xB2: output += char(225); break; // β (beta) → 225
case 0xB4: output += char(235); break; // δ (delta) → 235
case 0xB5: output += char(238); break; // ε (epsilon) → 238
case 0xBC: output += char(230); break; // μ (mu) → 230
case 0xC0: output += char(227); break; // π (pi) → 227
case 0xC3: output += char(229); break; // σ (sigma) → 229
case 0xC4: output += char(231); break; // τ (tau) → 231
case 0xC6: output += char(232); break; // φ (phi) → 232
default:
output += char(currentByte);
output += char(nextByte);
break;
}
} else if (currentByte == 0xCF && i + 1 < input.length()) {
// UTF-8 two-byte sequence for more Greek letters (0xCF)
i++; // Move to next byte
byte nextByte = (byte)input.charAt(i);
switch (nextByte) {
case 0x80: output += char(227); break; // π (pi) → 227
case 0x83: output += char(229); break; // σ (sigma) → 229
case 0x84: output += char(231); break; // τ (tau) → 231
case 0x86: output += char(232); break; // φ (phi) → 232
default:
output += char(currentByte);
output += char(nextByte);
break;
}
} else if (currentByte == 0xE2 && i + 2 < input.length()) {
// UTF-8 three-byte sequences for symbols and special characters
byte byte2 = (byte)input.charAt(i + 1);
byte byte3 = (byte)input.charAt(i + 2);
if (byte2 == 0x80) {
// General punctuation
switch (byte3) {
case 0x93: output += char(196); break; // – (en dash) → 196
case 0x94: output += char(196); break; // — (em dash) → 196
case 0x98: output += char(96); break; // ' (left single quote) → 96
case 0x99: output += char(39); break; // ' (right single quote) → 39
case 0x9C: output += char(34); break; // " (left double quote) → 34
case 0x9D: output += char(34); break; // " (right double quote) → 34
case 0xA2: output += char(249); break; // • (bullet) → 249
case 0xA6: output += char(46); break; // … (ellipsis) → 46
case 0xB0: output += char(137); break; // ‰ (per mille) → 137
default:
output += char(currentByte);
output += char(byte2);
output += char(byte3);
break;
}
i += 2; // Skip next two bytes
} else if (byte2 == 0x82) {
// Currency symbols
switch (byte3) {
case 0xAC: output += char(15); break; // € (Euro) → 15
default:
output += char(currentByte);
output += char(byte2);
output += char(byte3);
break;
}
i += 2; // Skip next two bytes
} else if (byte2 == 0x84) {
// Fractions and mathematical symbols
switch (byte3) {
case 0x83: output += char(252); break; // ⅓ → 252
case 0x85: output += char(172); break; // ⅕ → 172
case 0x86: output += char(171); break; // ⅙ → 171
case 0x87: output += char(243); break; // ⅐ → 243
case 0x89: output += char(251); break; // ⅑ → 251
default:
output += char(currentByte);
output += char(byte2);
output += char(byte3);
break;
}
i += 2; // Skip next two bytes
} else if (byte2 == 0x88) {
// Mathematical operators
switch (byte3) {
case 0x9A: output += char(251); break; // √ (square root) → 251
case 0x9E: output += char(236); break; // ∞ (infinity) → 236
case 0xA9: output += char(241); break; // ∩ (intersection) → 241
case 0xAB: output += char(247); break; // ∫ (integral) → 247
default:
output += char(currentByte);
output += char(byte2);
output += char(byte3);
break;
}
i += 2; // Skip next two bytes
} else if (byte2 == 0x89) {
// Mathematical operators continued
switch (byte3) {
case 0xA1: output += char(241); break; // ≡ (equivalent) → 241
case 0xA4: output += char(243); break; // ≤ (less than or equal) → 243
case 0xA5: output += char(242); break; // ≥ (greater than or equal) → 242
default:
output += char(currentByte);
output += char(byte2);
output += char(byte3);
break;
}
i += 2; // Skip next two bytes
} else if (byte2 == 0x94) {
// Box drawing characters (very common in CP437)
switch (byte3) {
case 0x80: output += char(196); break; // ─ → 196
case 0x82: output += char(179); break; // │ → 179
case 0x8C: output += char(218); break; // ┌ → 218
case 0x90: output += char(191); break; // ┐ → 191
case 0x94: output += char(192); break; // └ → 192
case 0x98: output += char(217); break; // ┘ → 217
case 0x9C: output += char(195); break; // ├ → 195
case 0xA4: output += char(180); break; // ┤ → 180
case 0xAC: output += char(194); break; // ┬ → 194
case 0xB4: output += char(193); break; // ┴ → 193
case 0xBC:
output += char(197);
break; // ┼ → 197
// case 0x80: output += char(205); break; // ═ → 205
case 0x91: output += char(186); break; // ║ → 186
default:
output += char(currentByte);
output += char(byte2);
output += char(byte3);
break;
}
i += 2; // Skip next two bytes
} else if (byte2 == 0x96) {
// Block elements
switch (byte3) {
case 0x80: output += char(176); break; // ░ → 176
case 0x84: output += char(177); break; // ▄ → 177
case 0x88: output += char(178); break; // █ → 178
case 0x8C: output += char(219); break; // ▌ → 219
case 0x90: output += char(220); break; // ▐ → 220
case 0x91: output += char(221); break; // ░ → 221
case 0x92: output += char(222); break; // ▒ → 222
case 0x93: output += char(223); break; // ▓ → 223
default:
output += char(currentByte);
output += char(byte2);
output += char(byte3);
break;
}
i += 2; // Skip next two bytes
} else {
// Unknown three-byte sequence
output += char(currentByte);
output += char(byte2);
output += char(byte3);
i += 2; // Skip next two bytes
}
} else {
// Single byte character > 127 or unknown multi-byte sequence
output += char(currentByte);
}
}
return output;
}